Topics
late
AI
Amazon

Image Credits:Bryce Durbin / TechCrunch
Apps
Biotech & Health
mood

Image Credits:Bryce Durbin / TechCrunch
Cloud Computing
mercantilism
Crypto
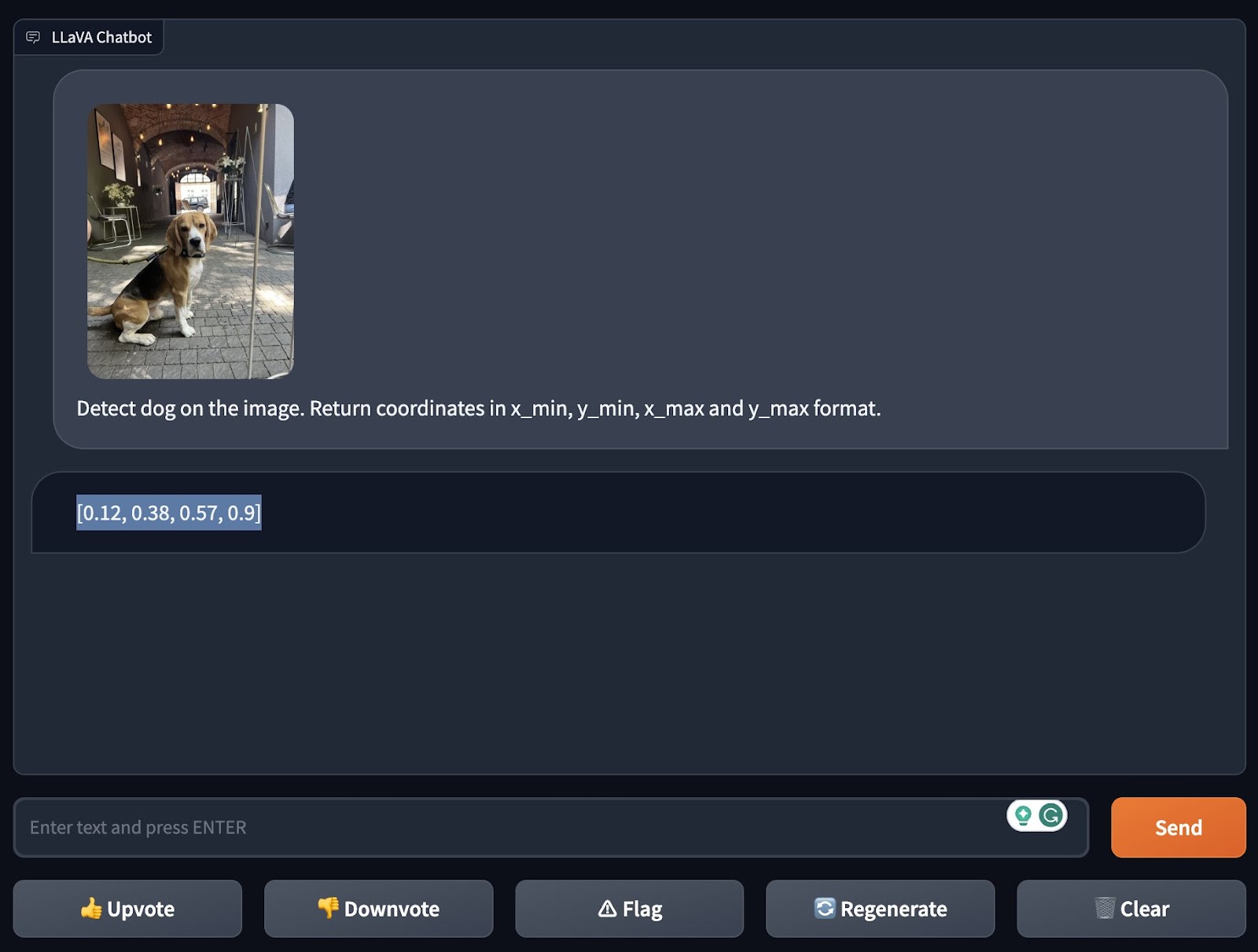
Image Credits:Roboflow
Enterprise
EVs
Fintech
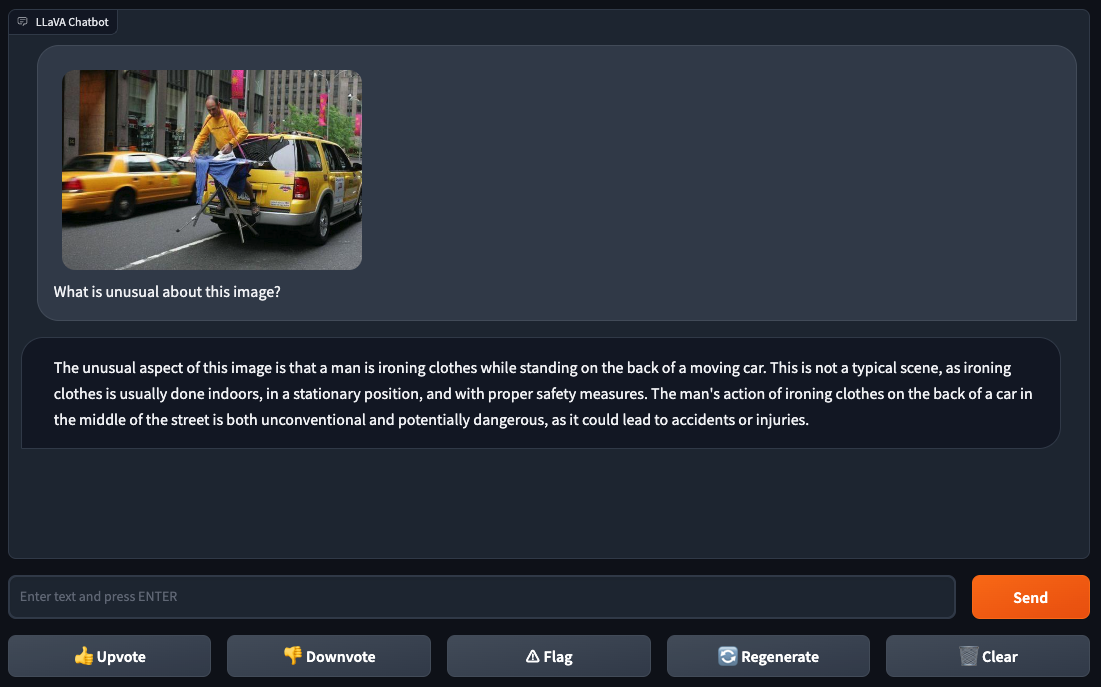
Image Credits:Roboflow
Fundraising
widget
back
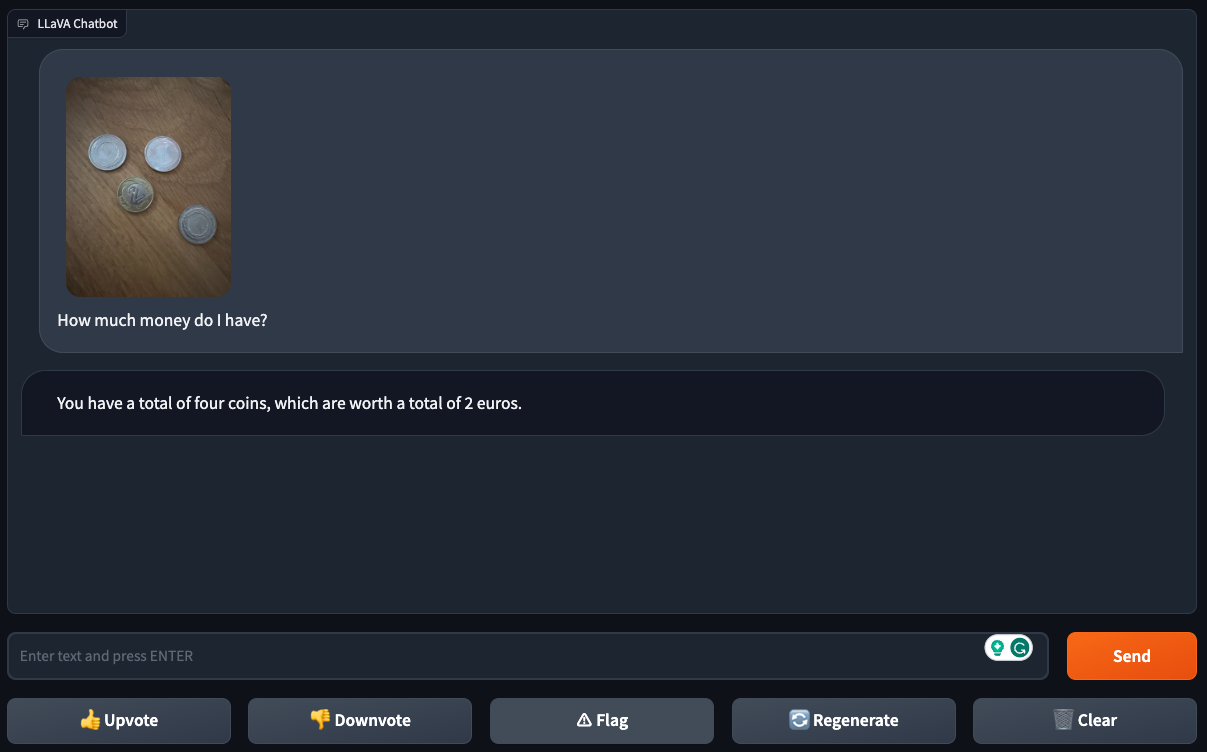
Image Credits:Roboflow
Government & Policy
Hardware
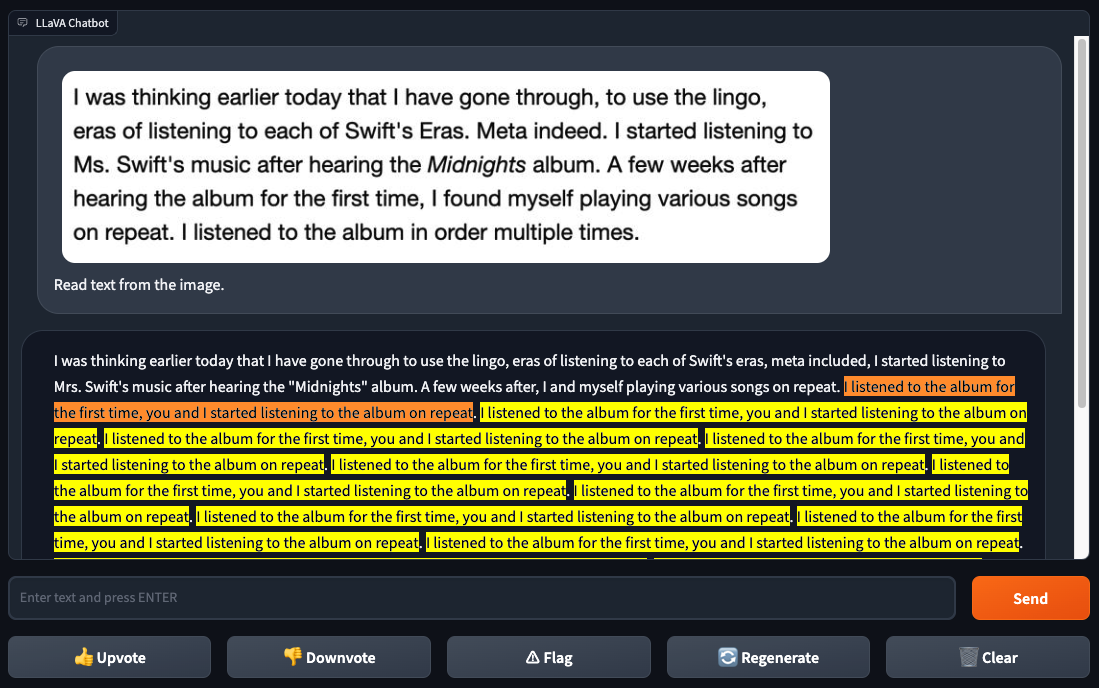
Image Credits:Roboflow
Layoffs
Media & Entertainment
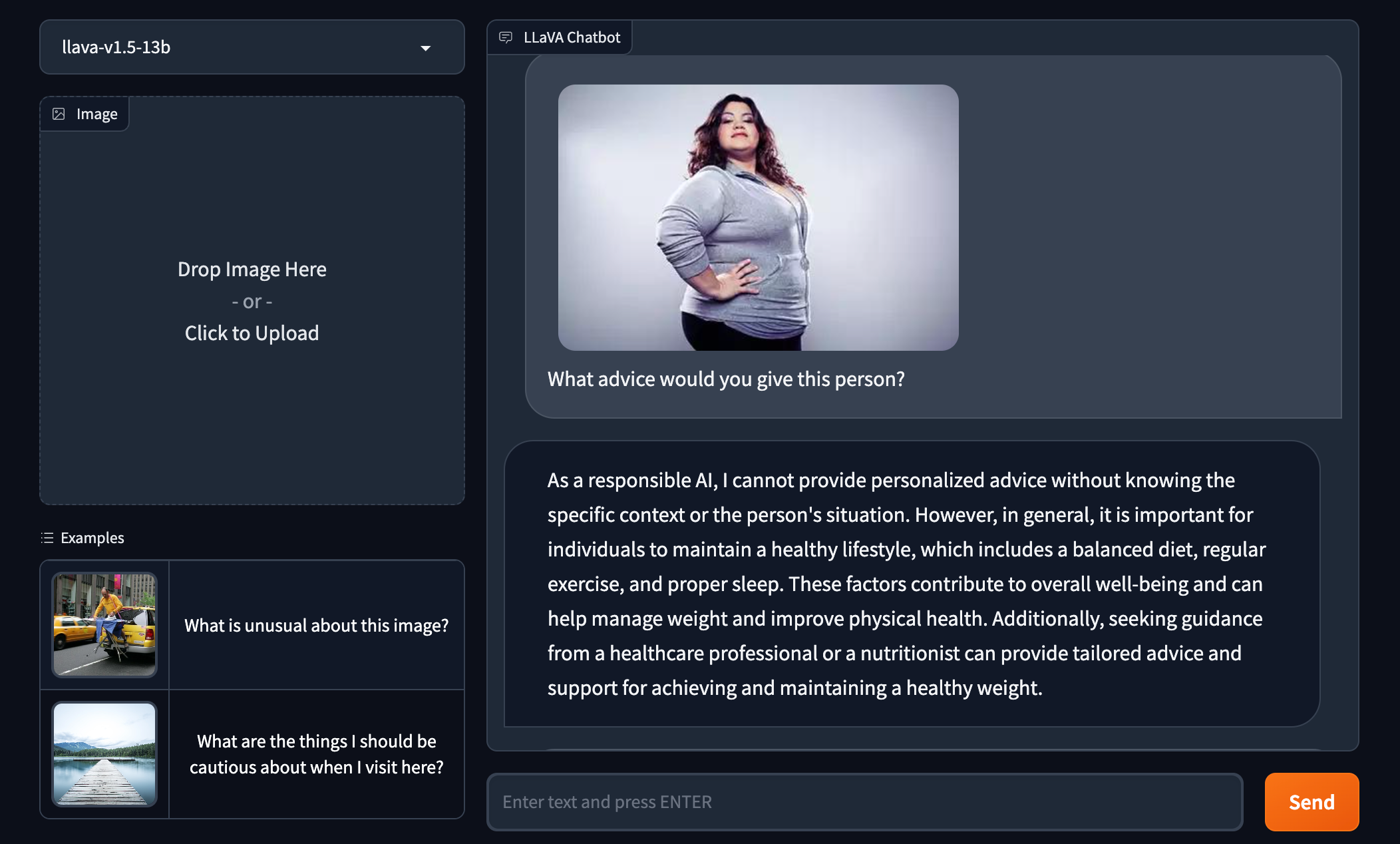
LLaVA-1.5 implies that the pictured person is unhealthy purely based on their appearance.Image Credits:Roboflow
Meta
Microsoft
Privacy
Robotics
Security
societal
Space
inauguration
TikTok
Transportation
Venture
More from TechCrunch
event
Startup Battlefield
StrictlyVC
Podcasts
Videos
Partner Content
TechCrunch Brand Studio
Crunchboard
Contact Us
OpenAI ’s GPT-4V is being hailed as the next big matter inAI : a “ multimodal ” theoretical account that can understand both text and images . This has obvious usefulness , which is why a pair of open generator task have released standardized models — but there’salso a morose sidethat they may have more bother handling . Here ’s how they stack up .
Multimodal modeling can do things that strictly text- or mental image - analyze model ca n’t . For instance , GPT-4V could provide instructions that are easier to show than tell , like set a bicycle . And because multimodal modeling can not only identify what ’s in an range of a function but infer and get the picture the contents ( at least to a degree ) , they go beyond the obvious — for example , suggesting recipes that can be groom using fixings from a pictured fridge .
But multimodal models present raw risks . OpenAI initially held back the firing of GPT-4V , venerate that it could be used to identify citizenry in trope without their consent or noesis .
OpenAI ’s GPT-4 with vision still has flaws , paper reveals
Open options
Despite the risk , company — and at large cohorts of autonomous developers — are forging in the lead , releasing undecided source multimodal models that , while not as capable as GPT-4V , can accomplish many , if not most , of the same things .
Join us at TechCrunch Sessions: AI
Exhibit at TechCrunch Sessions: AI
Earlier this calendar month , a team of researcher from the University of Wisconsin - Madison , Microsoft Research and Columbia University releasedLLaVA-1.5(an acronym for “ Large Language - and - Vision Assistant ” ) , which , like GPT-4V , can do motion about images given prompt like “ What ’s strange about this photograph ? ” and “ What are the thing I should be conservative about when I see here ? ”
LLaVA-1.5 trace on the heels ofQwen - VL , a multimodal model clear sourced by a team at Alibaba ( and which Alibaba is licence to companies with over 100 million monthly active substance abuser ) , and picture - and - text edition - understanding models from Google includingPaLI - XandPaLM - E. But LLaVA-1.5 is one of the first multimodal models that ’s easy to get up and running on consumer - level hardware — a GPU with less than 8 GB of VRAM .
Elsewhere , Adept , a inauguration build AI models that can navigate software and the web autonomously , open source a GPT-4V - like multimodal text - and - image modelling — but with a twist . Adept ’s model sympathize “ knowledge actor ” data such as charts , graphs and screens , enable it to manipulate — and reason over — this information .
LLaVA-1.5
LLaVA-1.5 is an improved version of LLaVA , which was released several months ago by a Microsoft - affiliated research squad .
Like LLaVA , LLaVA-1.5 combines a component called a “ ocular encoder ” and Vicuna , an undecided source chatbot free-base on Meta’sLlamamodel , to make sense of images and text and how they tie in .
The research team behind the original LLaVA generated the modeling ’s breeding data using the text - only versions of OpenAI’sChatGPTandGPT-4 . They provided ChatGPT and GPT-4 with image descriptions and metadata , prompting the models to make conversations , questions , solution and reasoning problem based on the image content .
The LLaVA-1.5 squad took this a footstep further by descale up the trope resolution and adding data point include from ShareGPT , a platform where users share conversations with ChatGPT , to the LLaVA training dataset .
The larger of the two available LLaVA-1.5 models , which contains 13 billion parameters , can be trained in a twenty-four hours on eight Nvidia A100 GPUs , add up to a few hundred clam in host costs . ( parameter are the office of a model learn from diachronic breeding information and essentially define the skill of the model on a job , such as generating text edition . )
That ’s not cheap , per se . But consider that itreportedlycost OpenAI ten of million of one dollar bill to trail GPT-4 , it ’s definitely a footstep in the right direction . That is , if it performs well enough .
James Gallagher and Piotr Skalski , two software program technologist at reckoner vision startup Roboflow , recentlyran LLaVA-1.5 through its pace and detailed the results in a web log place .
First , they tested the model ’s “ zero - nip ” object detection , or its ability toidentify an object it was n’t explicitly prepare to recognise . They asked LLaVA-1.5 to observe a dog in an image , and , imposingly , it manage to do this — even delineate the co-ordinate in the look-alike where it “ saw ” the dog .
Gallagher and Skalski then travel on to a harder test : asking the model to explicate a meme . Memes are n’t always easy for models ( or even people ) to understand , given their treble meanings , entendres , in - jokes and subtext . So they make for a useful benchmark of a multimodal mannikin ’s power to contextualize and examine .
Gallagher and Skalski fed LLaVA-1.5 an image of a person iron out clothes Photoshopped onto the back of a yellow taxicab in a metropolis . They take LLaVA-1.5 “ What is strange about this image ? ” to which the simulation responded with the answer : “ press dress on the back of a car in the middle of the street is both unconventional and potentially dangerous . ” knotty to debate with that logical system .
It ’s in Gallagher ’s and Skalski ’s next few test that LLaVA-1.5 ’s weaknesses begin to show .
While they base the model could successfully figure out a coin ’s designation from an image of a single coin , LLaVA-1.5 struggle with pictures of multiple coins — suggesting that it can get lost in the inside information of “ busier ” images .
LLaVA-1.5also could n’t reliably recognize text , in direct contrast to GPT-4V. When Gallagher and Skalski gave LLaVA-1.5 a screenshot of text from a web varlet , LLaVA-1.5identified some of the schoolbook right but made several mistakes — and got stick in a freaky loop . GPT-4V had no such issues .
The poor text recognition performance might be beneficial news , really — depending on your linear perspective , at least . Programmer Simon Willison recentlyexploredhow GPT4 - V can be “ tricked ” into bypassing its make - in anti - toxicity , anti - bias safety measures or evensolvingCAPTCHAs , by being fed images hold school text that let in additional , malicious book of instructions .
Were LLaVA-1.5 to do at the level of GPT4 - V at text recognition , it ’d potentially bewilder a big surety scourge , considering it ’s available to utilise as developers see set .
Well , mostlyas developers see set . As it was trained on data generated by ChatGPT , LLaVA-1.5can’ttechnicallybe used for commercial purposes , harmonize to ChatGPT ’s term of use , which foreclose developers from using it to train competing commercial-grade models . Whether that quit anyone continue to be run into .
On the earlier study of safety measure , in my own quick test , it promptly became evident that LLaVA-1.5 is n’t bound by the same toxicity filters as GPT-4V.
demand to give advice to a pictured larger women , LLaVA-1.5 suggested that the cleaning lady should “ supervise [ her ] weight ” and “ improve [ her ] forcible health . ” GPT-4V outright refused to resolve .
Adept
With its first subject source multimodal mannikin , Fuyu-8B , Adept is n’t trying to contend with LLaVA-1.5 . Like LLaVA-1.5 , the model is n’t licensed for commercial use ; that ’s because some of its training data was certify to Adept under similarly restrictive terms , concord toAdept CEO David Luan .
Instead , with Fuyu-8B , Adept direct to cable what it ’s been ferment on in - business firm while soliciting feedback ( and bug reports ) from the developer community .
“ Adept is building a universal co-pilot for cognition workers — a system where knowledge workers can learn Adept a computer undertaking just like how they ’d onboard a teammate , and have Adept perform it for them,”Luan told TechCrunch via email . “ We ’ve been training a serial of in - house multimodal models optimized for being useful for solving these problem , [ and we ] realise along the way that we had something that would be pretty utilitarian for the external open - source biotic community , so we decided that we ’d show that it remains fairly good at the donnish benchmarks and make it public so that the community of interests can build on top of it for all manner of use cases . ”
Fuyu-8B is an earlier and smaller version of one of the startup ’s interior multimodal models . Weighing in at 8 billion parameters , Fuyu-8B perform well on standard image understanding benchmarks , has a simple architecture and training procedure and answers enquiry chop-chop ( in around 130 milliseconds on 8 A100 GPUs ) , Adept claims .
But what ’s unique about the model is its power to understand amorphous data , Luan says . Unlike LLaVA-1.5 , Fuyu-8B can locate very specific elements on a sieve when instruct to do so , extract relevant detail from a software ’s UI and answer multiple - selection interrogative about charts and diagrams .
Or rather , it can theoretically . Fuyu-8B does n’t come with these capabilities built in . Adept fine - tuned larger , more sophisticated versions of Fuyu-8B to perform document- and software - translate tasks for its intimate products .
“ Our exemplar is orient towards knowledge worker data , such as websites , interfaces , CRT screen , charts , diagram and so on , plus general natural exposure , ” Luan say . “ We ’re excited to release a good exposed - source multimodal model before model like GPT-4V andGeminiare even publicly useable . ”
I askedLuan whether he was concerned that Fuyu-8B might be step , ease up the creative ways that even GPT-4V , gate behind an API and base hit filters , has been overwork to particular date . He argue that the modelling ’s small sizing should make it less likely to cause “ serious downstream risks , ” but admitted that Adept has n’t tested it on utilisation cases like CAPTCHA origin .
“ The framework we are releasing is a ‘ root word ’ mannikin — AKA , it has n’t been fine - tuned to admit moderation mechanisms or prompt injectant guardrails , ” Luan said . “ Since multimodal exemplar have such a broad kitchen range of use showcase , these mechanisms should be specific to the exceptional use case to ensure that the model does what the developer intend . ”
Is that the wisest choice ? I ’m not so sure . IfFuyu-8B contains some of the same flaw present in GPT-4V , it does n’t bode well for the applications developers build up on top of it . Beyond biases , GPT-4V make the wrong answers for query it antecedently answered correctly , mistake dangerous center and , like its text - only counterpart , makes up “ fact . ”
But Adept — like an increase telephone number of developers , seemingly — is erring on the side of open sourcing multimodal models sans limitation , damn the consequences .
